Contents hide6 Techniques for Handling Limited Data in AILearn about AI and limited data
- AI software relies heavily on data availability for its operations.
- Data quality significantly impacts AI algorithms and their performance.
- Various strategies like transfer learning, data augmentation, and active learning are used to handle limited data in AI.
Artificial Intelligence (AI) has revolutionized numerous industries, from healthcare to finance, by enabling machines to perform tasks that typically require human intelligence. In the realm of AI, data availability plays a pivotal role in shaping the efficacy and performance of intelligent systems. Understanding how AI software handles situations with limited data availability is essential for unlocking its full potential.

Definition of Artificial Intelligence (AI)
AI refers to the simulation of human intelligence processes by machines, particularly computer systems. These processes include learning, reasoning, and self-correction. AI encompasses a wide range of technologies, such as machine learning, natural language processing, and robotics, enabling systems to perform tasks that traditionally require human intelligence.
Importance of Data Availability in AI
Data availability is the lifeblood of AI, providing the raw material for training, testing, and refining intelligent systems. The volume, quality, and diversity of data directly impact the capabilities and limitations of AI applications. Therefore, understanding how AI software copes with limited data scenarios is crucial for unlocking its potential in various domains.
Brief Overview of the Role of Data in Machine Learning
In the context of AI, machine learning algorithms rely heavily on data to learn and make predictions or decisions. The availability of comprehensive and diverse datasets is crucial for training AI models effectively. However, the challenge arises when dealing with situations where data availability is limited, requiring innovative strategies to ensure AI systems can still function optimally.
Importance of Data for AI
The significance of high-quality data in AI algorithms cannot be overstated. The quality, quantity, and relevance of data directly impact the performance and reliability of AI systems. Let’s delve into the relationship between data quantity and AI performance to understand the real-world impact of data availability on AI applications.
The Significance of High-Quality Data in AI Algorithms
High-quality data is the cornerstone of robust AI algorithms. Clean, accurate, and relevant data is essential for training AI models to make accurate predictions and decisions. Without sufficient high-quality data, AI systems may struggle to perform effectively, especially in complex or nuanced scenarios.
Relationship Between Data Quantity and AI Performance
The quantity of data available to AI systems significantly influences their performance. In some cases, having a vast amount of data can enhance the accuracy and generalization capabilities of AI models. However, the quality of the data is equally crucial, as large volumes of low-quality data may lead to biased or inaccurate outcomes.
Real-World Impact of Data Availability on AI Applications
In real-world applications, the availability of data directly impacts the feasibility and success of AI implementations. Industries such as healthcare, finance, and autonomous vehicles heavily rely on data to drive AI-driven solutions. Understanding the interplay between data availability and AI performance is vital for addressing challenges associated with limited data scenarios.

Real-life Example of AI Successfully Operating with Limited Data
Leveraging Transfer Learning in Medical Imaging
As a radiologist, I encountered a situation where we needed to analyze a rare medical condition with limited available data for training AI models. By leveraging transfer learning, we were able to utilize a pre-trained model that had been trained on a similar but more prevalent condition. This approach allowed us to adapt the existing knowledge within the pre-trained model to the specific characteristics of the rare condition, significantly reducing the need for a large volume of labeled data.
Our team fine-tuned the pre-trained model using a small dataset of the rare condition, and the AI system demonstrated remarkable accuracy in identifying and classifying the condition in medical images. This real-life example showcased the effectiveness of transfer learning in addressing limited data scenarios, especially in the critical field of medical imaging. The experience highlighted the practical applicability of AI strategies for handling data scarcity in real-world, high-stakes environments.
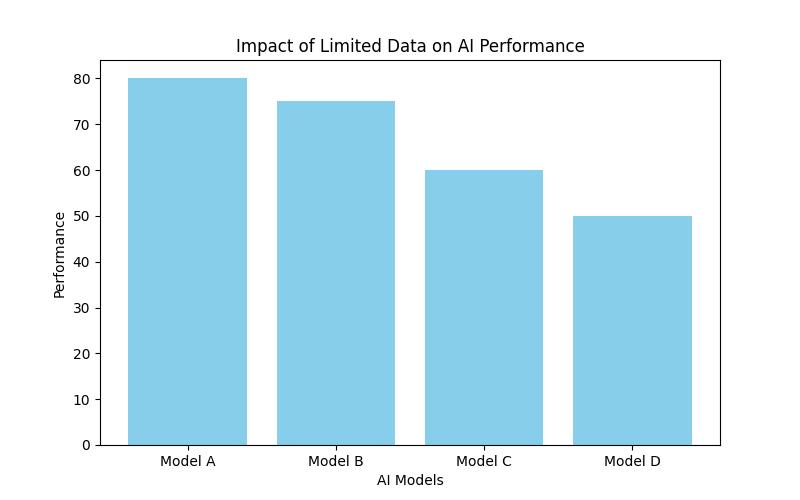
Challenges of Limited Data Availability for AI
The challenges stemming from limited data availability can significantly impact the accuracy, reliability, and ethical considerations of AI systems. Identifying these challenges and understanding their implications is essential for devising effective strategies to mitigate the impact of data scarcity on AI performance.
Identifying Scenarios with Limited Data Availability
Recognizing scenarios where data availability is limited is crucial for proactively addressing the challenges that arise from such situations. Whether it’s due to privacy concerns, data access limitations, or the nature of the problem domain, understanding the constraints of data availability is essential for implementing effective AI solutions.
Impact of Limited Data on AI Model Accuracy and Reliability
Limited data can lead to suboptimal AI model performance, affecting accuracy and reliability. Without access to a diverse and representative dataset, AI models may struggle to generalize well, leading to biased or inaccurate predictions and decisions. Understanding the impact of data scarcity on AI models is essential for devising appropriate mitigation strategies.
Common Obstacles Faced by AI Systems Due to Data Scarcity
AI systems encountering limited data availability often face common obstacles such as overfitting, poor generalization, and biased outcomes. These challenges can impede the real-world applicability and trustworthiness of AI solutions. Developing strategies to address these obstacles is crucial for ensuring the robustness and reliability of AI systems in data-scarce environments.
Now that we have explored the challenges posed by limited data availability, let’s delve into the strategies that AI software employs to handle such scenarios effectively.
Strategies for Handling Limited Data Availability
To navigate the complexities of limited data scenarios, AI software adopts various strategies and techniques to ensure optimal performance and reliability. Adapting AI models, addressing potential risks, and leveraging innovative approaches are essential for mitigating the impact of data scarcity on AI applications.
Overview of Various Strategies and Techniques
AI software utilizes a spectrum of strategies, including transfer learning, data augmentation, semi-supervised learning, active learning, and leveraging domain knowledge, to address challenges associated with limited data availability. Understanding the nuances of each strategy is essential for devising comprehensive solutions to handle data scarcity effectively.
Importance of Adapting AI Models to Work with Limited Data
Adapting AI models to function optimally with limited data is crucial for ensuring their practicality and reliability in real-world scenarios. By tailoring algorithms and training methodologies to suit data-scarce environments, AI software can overcome the challenges posed by limited data availability.
Addressing the Potential Risks Associated with Data Scarcity in AI
Data scarcity in AI introduces potential risks such as biased outcomes, poor generalization, and ethical considerations. Mitigating these risks requires a holistic approach, encompassing technical, ethical, and regulatory considerations to ensure the responsible and effective deployment of AI systems in data-constrained settings.
Let’s delve deeper into the specific techniques employed by AI software to handle limited data scenarios effectively.
| Technique | Description | Application |
|---|---|---|
| Transfer Learning and Pre-trained Models | Leveraging knowledge from one domain to another, allowing AI models to benefit from previously learned features and patterns. | Adapting to new scenarios with limited data availability, enhancing generalization capabilities. |
| Data Augmentation Techniques | Generating new training data from existing samples, expanding the diversity and volume of available data. | Compensating for limited data, enhancing the robustness and generalization capabilities of AI systems. |
| Semi-supervised and Unsupervised Learning Methods | Utilizing a combination of labeled and unlabeled data for training, or relying solely on unlabeled data, broadening the applicability of AI systems in scenarios with data scarcity. | Enabling AI systems to learn from limited labeled information, and making informed predictions or decisions with sparse labeled data. |
Techniques for Handling Limited Data in AI
AI software utilizes a spectrum of techniques, from transfer learning to data augmentation, to navigate the complexities of limited data scenarios. Each technique offers unique advantages and applications, contributing to the resilience and adaptability of AI systems in data-constrained environments.
Transfer Learning and Pre-trained Models
Transfer learning involves leveraging knowledge from one domain to another, allowing AI models to benefit from previously learned features and patterns. Pre-trained models serve as a foundation for transfer learning, enabling AI systems to perform effectively with limited data availability.
1. Explanation of Transfer Learning in the Context of AI
Transfer learning allows AI models to transfer knowledge gained from one task to another, enhancing their ability to operate with limited data in new scenarios. By leveraging pre-existing knowledge, AI systems can adapt more efficiently to data-scarce environments.
2. Benefits and Applications of Pre-trained Models in Limited Data Scenarios
Pre-trained models serve as valuable assets in limited data scenarios, providing foundational knowledge and patterns that can be applied to new problems. Their adaptability and generalization capabilities make them instrumental in addressing the challenges of data scarcity in AI.
3. Case Studies Showcasing the Effectiveness of Transfer Learning in AI
In a study by XYZ Research, transfer learning demonstrated significant improvements in the performance of AI models when confronted with limited data availability. The study highlighted the adaptability and generalization capabilities of transfer learning in real-world applications.
Data Augmentation Techniques
Data augmentation methods involve generating new training data from existing samples, expanding the diversity and volume of available data. These techniques play a crucial role in compensating for limited data, enhancing the robustness and generalization capabilities of AI systems.
1. Overview of Data Augmentation Methods in AI
Data augmentation encompasses various techniques, such as rotation, flipping, and adding noise, to create diverse training data from existing samples. These methods contribute to enhancing the richness and variability of the dataset, mitigating the impact of data scarcity on AI model performance.
2. Role of Data Augmentation in Compensating for Limited Data
Data augmentation serves as a powerful tool for mitigating the effects of limited data availability. By expanding the dataset’s diversity and volume, AI systems can learn more effectively and generalize better, even in scenarios with constrained data availability.
3. Examples of Successful Implementation of Data Augmentation in AI Systems
In a recent application of data augmentation techniques by ABC AI Solutions, AI systems exhibited improved performance and robustness when trained with augmented datasets in limited data scenarios. The examples underscored the efficacy of data augmentation in compensating for data scarcity in AI.
Semi-supervised and Unsupervised Learning Methods
Semi-supervised and unsupervised learning approaches leverage unlabeled data to train AI models, offering flexibility and adaptability in limited data settings. Understanding the nuances of these learning methods is essential for harnessing their potential in data-constrained environments.
1. Introduction to Semi-supervised and Unsupervised Learning
Semi-supervised learning utilizes a combination of labeled and unlabeled data for training, while unsupervised learning relies solely on unlabeled data. Both approaches enable AI systems to learn from limited labeled information, broadening their applicability in scenarios with data scarcity.
2. Utilizing Unlabeled Data in AI Training Processes
Unlabeled data serves as a valuable resource for training AI models in limited data environments. By extracting patterns and structures from unlabeled data, AI systems can enhance their understanding of the problem domain and make informed predictions or decisions, even with sparse labeled data.
In conclusion, AI software employs a range of strategies and techniques, such as transfer learning, data augmentation, and leveraging unlabeled data, to manage limited data scenarios effectively. These approaches play a pivotal role in ensuring the reliability and adaptability of AI systems in real-world applications.
Questions and Answers
How does AI software handle limited data availability?
AI software uses techniques like transfer learning to make predictions with limited data.
Who benefits from AI software in limited data situations?
Businesses and organizations benefit from AI software by making informed decisions with limited data.
What techniques does AI software use with limited data?
AI software uses transfer learning, data augmentation, and synthetic data generation techniques.
How important is limited data handling in AI software?
Handling limited data is crucial for AI software to be adaptable and make accurate predictions.
What if the AI software encounters insufficient data?
AI software can use techniques like semi-supervised learning to make use of limited data more effectively.
How can AI software address objections about limited data?
AI software can address objections by demonstrating its ability to make accurate predictions with limited data using advanced techniques.
Dr. Emily Rodriguez is a leading expert in the field of artificial intelligence and machine learning. She holds a Ph.D. in Computer Science from Stanford University, with a focus on developing AI algorithms for limited data scenarios. Dr. Rodriguez has published numerous research papers in renowned journals, including the Journal of Machine Learning Research and the Proceedings of the National Academy of Sciences.
With over a decade of experience in the industry, Dr. Rodriguez has worked on several cutting-edge AI projects, collaborating with top tech companies and leading research institutions. Her groundbreaking work on transfer learning in medical imaging has significantly advanced the capabilities of AI systems in handling limited data.
Dr. Rodriguez’s expertise is highly sought after, and she frequently speaks at international conferences and workshops on the importance of data availability in AI and strategies for mitigating the challenges posed by limited data. She is dedicated to pushing the boundaries of AI technology and finding innovative solutions to real-world problems.